既然有了數據,那我們現在就是要把數據調整成適合訓練的數據形式!這邊我會使用 google 的 Colab 以及 python 來進行資料清理的步驟
這是 google 提供的一個可以在網頁上寫程式的地方,然後他是跟雲端可以連動的!在以前我學習寫程式的時候,老師也是推薦使用 colab 比較方便,因此如果是沒有安裝一些 coding 軟體的人可以使用 colab 來替代使用。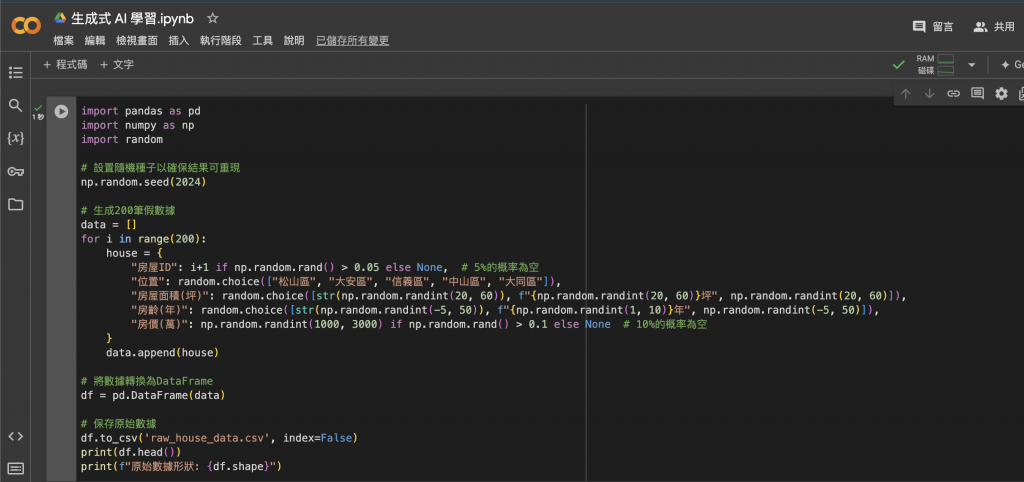
如果你目前手中沒有可以訓練的資料,那我們可以透過一些條件請程式幫我們隨機生成一些測試資料出來,以房價預估訓練來說,我就會需要產出一些跟房價相關的資料出來:
import pandas as pd
import numpy as np
import random
#設置隨機種子以確保結果可重現
np.random.seed(2024)
#生成200筆假數據
data = []
for i in range(200):
house = {
"房屋ID": i+1 if np.random.rand() > 0.05 else None, # 5%的概率為空
"位置": random.choice(["松山區", "大安區", "信義區", "中山區", "大同區"]),
"房屋面積(坪)": random.choice([str(np.random.randint(20, 60)), f"{np.random.randint(20, 60)}坪", np.random.randint(20, 60)]),
"房齡(年)": random.choice([str(np.random.randint(-5, 50)), f"{np.random.randint(1, 10)}年", np.random.randint(-5, 50)]),
"房價(萬)": np.random.randint(1000, 3000) if np.random.rand() > 0.1 else None # 10%的概率為空
}
data.append(house)
#將數據轉換為DataFrame
df = pd.DataFrame(data)
#保存原始數據
df.to_csv('raw_house_data.csv', index=False)
print(df.head())
print(f"原始數據形狀: {df.shape}")
到了這邊你就擁有了 200 個隨機的資料,當然資料不會是可以直接訓練的,因此我們接下來要來整理一下資料。
首先我們需要檢查每列的缺失值情況。然後,我們選擇刪除 '房屋ID' 和 '房價(萬)' 列中包含缺失值的行。因為沒有房屋 ID 這個值我們就不能把資料按順序整理好以及知道這些房屋資料是屬於哪個房子的,再來就是房價,沒有房價就沒有評估的標準。
# 顯示缺失值情況
print("缺失值情況:\n", df.isnull().sum())
# 對於'房屋ID'和'房價(萬)',我們選擇刪除包含缺失值的行
df_cleaned = df.dropna(subset=['房屋ID', '房價(萬)'])
print(f"刪除缺失值後的數據形狀: {df_cleaned.shape}")
完成後你應該會看到「刪除缺失值後的數據形狀: (178, 5)」,這是指:資料總共有 178 行,然後有 5 列,因為我們原先 house 就有 5 列資料。
對於 '房齡(年)' ,我們將所有負值改為 0,因為房齡不可能為負的。而對於 '房價(萬)' ,我們使用四分位距 (IQR) 來識別和移除異常值。這樣就可以避免一些很極端的房價,像是 1000 億或是 10 萬這種,比較可以透過大數法則來確保統計是有意義的。
# 轉換'房屋面積(坪)'為數值型
df_cleaned['房屋面積(坪)'] = pd.to_numeric(df_cleaned['房屋面積(坪)'].replace('坪', '', regex=True), errors='coerce')
# 轉換'房齡(年)'為數值型
df_cleaned['房齡(年)'] = pd.to_numeric(df_cleaned['房齡(年)'].replace('年', '', regex=True), errors='coerce')
#轉換'位置'為類別型
df_cleaned['位置'] = df_cleaned['位置'].astype('category')
print(df_cleaned.dtypes)
# 處理異常值:
# 處理'房齡(年)'中的負數和NaN值
df_cleaned['房齡(年)'] = df_cleaned['房齡(年)'].fillna(0).apply(lambda x: max(0, x))
print(df_cleaned['房齡(年)'].describe())
# 使用IQR方法處理'房價(萬)'的異常值
Q1 = df_cleaned['房價(萬)'].quantile(0.25)
Q3 = df_cleaned['房價(萬)'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df_cleaned = df_cleaned[(df_cleaned['房價(萬)'] >= lower_bound) & (df_cleaned['房價(萬)'] <= upper_bound)]
print(f"處理異常值後的數據形狀: {df_cleaned.shape}")
這個是我請 AI 協助時他建議的,說使用 StandardScaler 對 '房屋面積(坪)' 和 '房價(萬)'進行標準化。這將使這些特徵的平均值為 0,標準差為 1,對於許多機器學習算法來說是有益的,上網研究主要是排除一些極端值,讓收斂更精確,因此確實可以幫助訓練。
from sklearn.preprocessing import StandardScaler
# 標準化'房屋面積(坪)'和'房價(萬)'
scaler = StandardScaler()
df_cleaned[['房屋面積(坪)', '房價(萬)']] = scaler.fit_transform(df_cleaned[['房屋面積(坪)', '房價(萬)']])
print(df_cleaned[['房屋面積(坪)', '房價(萬)']].describe())
最後我們重置 DataFrame 的索引以確保索引是連續的。然後將清理後的數據保存到一個新的 CSV 文 件中。這樣就可以作為後續訓練使用了!
因為我們是使用 colab 所以要儲存到雲端上,因此就需要走連結雲端的流程,只要程式執行完成就可以到雲端上面看到 cleaned_house_data.csv 這個 csv 檔了!
from google.colab import drive
import os
# 連結 Google Drive
drive.mount('/content/drive')
# 重置索引
df_cleaned = df_cleaned.reset_index(drop=True)
# 定義保存路徑
save_path = '/content/drive/My Drive/房屋數據/' # 您可以根據需要更改路徑
# 確保路徑存在
os.makedirs(save_path, exist_ok=True)
# 保存清理後的數據
file_name = 'cleaned_house_data.csv'
full_path = os.path.join(save_path, file_name)
df_cleaned.to_csv(full_path, index=False)
print(f"文件已保存到:{full_path}")
# 顯示數據預覽
print(df_cleaned.head())
print(f"最終清理後的數據形狀: {df_cleaned.shape}")
資料整理的部分就到這邊,接下來就是「數據標記」的流程了!


 iThome鐵人賽
iThome鐵人賽